「データはある、でもAIに読めない」
REWIRE I(Intelligence)が問う組織知識基盤の設計
エージェントAIの普及が露わにした「知識の問題」
AIエージェントの導入が本格化する中で、ひとつの共通した課題が浮かび上がっている。
MIT Technology Reviewが2026年3月に報告した調査によれば、エンタープライズAIがスケールしない主要因は「モデルの性能」ではなく、「AIエージェントにビジネスコンテキストを届けるデータアーキテクチャの欠如」だという。10社に1社しかAIエージェントをスケールできていないという現実の背景に、この構造的な問題があると感じている(MIT Technology Review, 2026)。
Deloitteの2026年AI調査(3,235人のシニアリーダーを対象)も同様の指摘をしている。レガシーなデータ・インフラアーキテクチャはリアルタイムで自律的なAIを支えられない。必要なのは、組織全体でリアルタイムに適応する「生きたAIバックボーン」だ、と(Deloitte, 2026)。
「データはある、でもAIに読めない」この状態の組織が、まだ多いのではないだろうか。
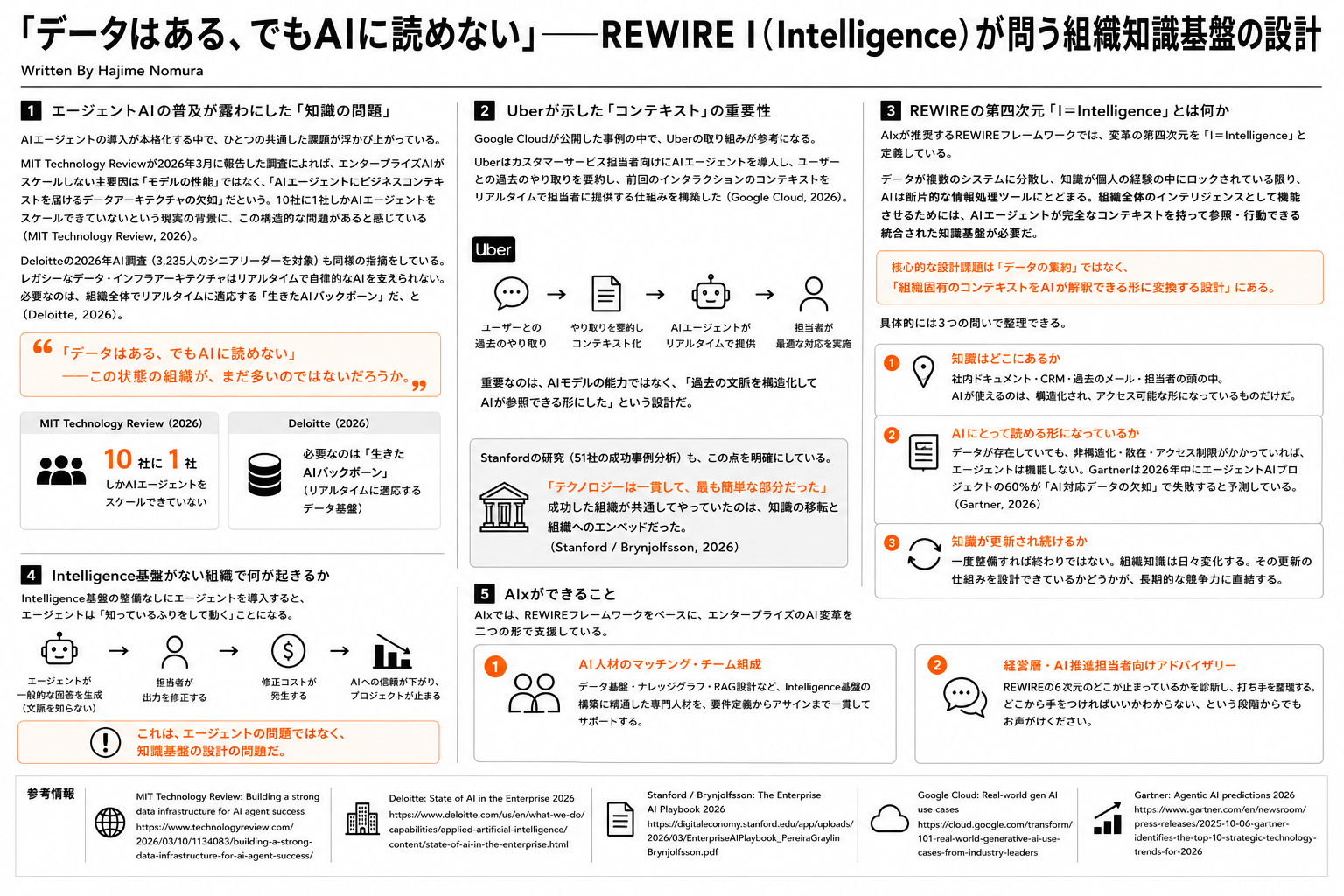
Uberが示した「コンテキスト」の重要性
Google Cloudが公開した事例の中で、Uberの取り組みが参考になると思っている。Uberはカスタマーサービス担当者向けにAIエージェントを導入し、ユーザーとの過去のやり取りを要約し、前回のインタラクションのコンテキストをリアルタイムで担当者に提供する仕組みを構築した(Google Cloud, 2026)。
ここで重要なのは、AIモデルの能力ではなく、「過去の文脈を構造化してAIが参照できる形にした」という設計だ。同じデータを持っていても、AIが解釈できる形に整理されていなければ、エージェントは機能しない。
Stanfordの研究(51社の成功事例分析)も、この点を明確にしている。「テクノロジーは一貫して、最も簡単な部分だった」。成功した組織が共通してやっていたのは、知識の移転と組織へのエンベッドだったという(Stanford / Brynjolfsson, 2026)。
REWIREの第四次元「I=Intelligence」とは何か
AIxが推奨するREWIREフレームワークでは、変革の第四次元を「I=Intelligence」と定義している。
データが複数のシステムに分散し、知識が個人の経験の中にロックされている限り、AIは断片的な情報処理ツールにとどまる。組織全体のインテリジェンスとして機能させるためには、AIエージェントが完全なコンテキストを持って参照・行動できる統合された知識基盤が必要だ。
核心的な設計課題は「データの集約」ではなく、「組織固有のコンテキストをAIが解釈できる形に変換する設計」にある。
具体的には3つの問いで整理できます。
・「知識はどこにあるか」。社内ドキュメント・CRM・過去のメール・担当者の頭の中。AIが使えるのは、構造化され、アクセス可能な形になっているものだけだ。
・「AIにとって読める形になっているか」。データが存在していても、非構造化・散在・アクセス制限がかかっていれば、エージェントは機能しない。Gartnerは2026年中にエージェントAIプロジェクトの60%が「AI対応データの欠如」で失敗すると予測している(Gartner, 2026)。
・「知識が更新され続けるか」。一度整備すれば終わりではない。組織知識は日々変化する。その更新の仕組みを設計できているかどうかが、長期的な競争力に直結すると感じている。
Intelligence基盤がない組織で何が起きるか
Intelligence基盤の整備なしにエージェントを導入すると、エージェントは「知っているふりをして動く」ことになる。社内ルール・例外処理・顧客固有の背景を知らないまま、一般的な回答を生成する。担当者がその出力を修正するコストが発生し、AIへの信頼が下がり、プロジェクトが止まる。
これは、エージェントの問題ではなく、知識基盤の設計の問題だ。
AIxができること
AIxでは、REWIREフレームワークをベースに、エンタープライズのAI変革を二つの形で支援しています。
① AI人材のマッチング・チーム組成 データ基盤・ナレッジグラフ・RAG設計など、Intelligence基盤の構築に精通した専門人材を、要件定義からアサインまで一貫してサポート。
② 経営層・AI推進担当者向けアドバイザリー REWIREの6次元のどこが止まっているかを診断し、打ち手を整理する。
どこから手をつければいいかわからない、という段階からでもお声がけください。
参考情報
MIT Technology Review: Building a strong data infrastructure for AI agent success — https://www.technologyreview.com/2026/03/10/1134083/building-a-strong-data-infrastructure-for-ai-agent-success/
Deloitte: State of AI in the Enterprise 2026 — https://www.deloitte.com/us/en/what-we-do/capabilities/applied-artificial-intelligence/content/state-of-ai-in-the-enterprise.html
Stanford / Brynjolfsson: The Enterprise AI Playbook 2026 — https://digitaleconomy.stanford.edu/app/uploads/2026/03/EnterpriseAIPlaybook_PereiraGraylinBrynjolfsson.pdf
Google Cloud: Real-world gen AI use cases — https://cloud.google.com/transform/101-real-world-generative-ai-use-cases-from-industry-leaders
Gartner: Agentic AI predictions 2026 — https://www.gartner.com/en/newsroom/press-releases/2025-10-06-gartner-identifies-the-top-10-strategic-technology-trends-for-2026